.jpeg)
I’ve sat in enough pipeline reviews to know exactly how the conversation goes. Sales says the leads aren’t ready. Marketing pulls up a dashboard and points to a set of agreed-upon scoring rules as proof that they are. And somewhere in that standoff, a real prospect, from a real target account, goes untouched for two weeks because everyone is busy arguing about who’s correct.
That argument almost always starts with the scoring model. A team installs a marketing automation platform, opens the lead scoring panel, sees a blank canvas, and immediately starts filling it with “industry standard” rules. Email clicked: +5 points. Blog post viewed: +3 points. Webinar attended: +10 points.
The problem is that most of the rules we were taught to use when building a lead scoring model don’t actually measure meaningful engagement. They measure noise. And noise, added to noise, just gets louder and drowns out the voices of the people you are looking for. The end outcome is that it sends the wrong leads to the top of your sales queue and creates friction between departments.
The problem is not new. For twenty years, the industry has been building scoring models that measure the wrong thing, and the pipeline review standoff is what that mistake looks like in practice. Don’t believe me? Let’s dive deeper:
Why Lead Scoring Actions Are Not the Same as Purchase Intent
A lead scoring model that rewards actions rather than intent is not a predictive model. It is an activity log with a threshold attached to it.
Every behavior your marketing automation platform (MAP) tracks is an action. Someone clicked a link. Someone downloaded a file. Someone spent four minutes on a page. These are actions, and marketing automation platforms are very good at recording actions.
What they cannot record is WHY those actions happened, and why is what matters for predicting a purchase. A click can mean genuine interest in your product or a security scanner swept the email before a human opened it. A content download can mean a buyer researching a shortlist or a student writing a paper. A webinar registration can mean someone evaluating your solution or someone who wanted the on-demand recording and will never engage again.
When you assign points to actions without accounting for whether those actions reflect intent to buy, you are not building a scoring model. You are building an activity tracker, and activity does not convert. Intent converts. The noise in your model is not a technical problem or a data quality problem, at least not primarily. It is a conceptual one: the model is measuring the wrong thing, and adding more rules to measure more of the wrong thing only makes the signal harder to find.

The Math of a Broken Lead Scoring Model
Let’s ground this in something concrete. Imagine your model requires 100 points to convert a lead to an MQL. You’ve set “email click” to +5 points. This is industry standard; nobody will question you. But here’s the question you should be asking: What is the actual relationship between clicking an email and purchasing your product?
In most B2B SaaS contexts, there is almost no relationship, because email clicks are corrupted at the source. Security tools auto-click every link in an email before a human ever sees it. Privacy features and spam filters pre-load pixels in ways that are indistinguishable from genuine human activity. A “click” event in your MAP is as likely to be automated as it is to be a buyer expressing genuine intent, which means every point you award for that action is awarded on a coin flip.
So when you award points for that click, here’s what you’re actually computing:
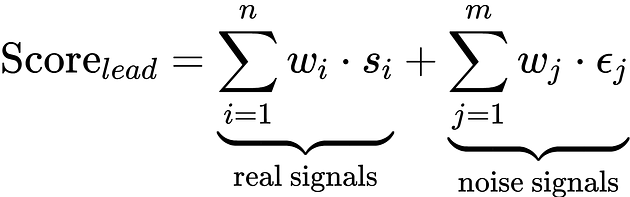
In non-scary math speak, it means that too much noise in your scoring model makes your leads look artificially engaged, making them appear interested even though they have no intent to buy.
The chart above illustrates what the research consistently shows: properly scored leads that reach sales based on genuine intent signals achieve conversion rates of around 40 percent, compared to roughly 11 percent for unqualified prospects. It is the difference between a sales team that trusts its queue and one that doesn’t.

How Noisy Lead Scoring Rules Inflate MQL Counts and Waste SDR Time
Here’s a scenario that plays out constantly at growth-stage SaaS companies. A lead from a Fortune 500 target account visits your pricing page once, reads a case study, and then goes quiet. Meanwhile, a grad student writing a thesis on your industry category downloads three ebooks, attends a webinar, clicks every nurture email, and visits your blog six times.
Under a typical point-heavy model, that grad student hits MQL threshold first. Your SDR wastes a week of outreach capacity chasing someone who will never have a budget conversation. The average MQL-to-SQL conversion rate in B2B SaaS sits at around 13 percent industry-wide, and for teams running noisy models it is often lower, because a meaningful share of what is reaching sales was never qualified to begin with.
The scoring math that produces this outcome looks like:
The model is weighting actions in the wrong proportions. A demo request earns 6x as many points as an email click, but the conversion correlation column suggests it should be closer to 18x. The model is systematically undervaluing its best signals while awarding points for behaviors that measure bot activity and researcher curiosity.
Lead Scoring Vanity Metrics Go Well Beyond Email Clicks
Email clicks get the most attention because the bot-click problem is so well-documented, but the underlying issue is much broader. Any time you score a behavior that is weakly associated with purchase intent but easy to produce at scale, you are injecting noise into your model. And noise, in a scoring system, makes the output unreliable in proportion to how many rules you stack.
Here is a partial list of vanity metrics I see polluting lead scoring models at early-stage companies:
The connecting thread across all of these vanity metrics is that they measure activity without measuring intent. They answer the question “did something happen?” rather than “is this person moving toward a purchase decision?” That distinction is what separates a lead scoring model that supports sales and marketing alignment from one that quietly undermines it.

How to Build a Lead Scoring Model That Actually Predicts Conversion
The fix begins with a simple reorientation of what the model is trying to predict. A lead score should be a compressed estimate of conversion probability, not a measure of how much someone has interacted with your brand. Those are different things, and optimizing for the latter while hoping it proxies the former is where most models go wrong.
A cleaner architecture separates the model into two components:
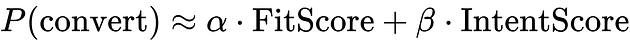
FitScore reflects ICP alignment (firmographics, technographics, role), and IntentScore reflects only high-correlation behaviors: pricing page visits, demo requests, trial activity, and bottom-funnel content consumption.
Everything else can be provided a behavioural infomation that informs your SDR of sequencing, but does not contribute to MQL threshold crossing. When you structure the model this way, the signal-to-noise ratio improves dramatically because you’ve stopped rewarding noise accumulation.
What Changes When the Model Is Honest
The solution is not to score less, it is to score differently. A rebuilt lead scoring model separates into two distinct components: a fit layer that scores ICP alignment using firmographic and technographic data, and an intent layer that scores only the handful of behaviors that actually correlate with a purchase decision. Pricing page visits, demo requests, trial activity, and bottom-funnel content consumption cross the MQL threshold. Everything else, the clicks, the ebook downloads, the blog views, the social follows, feeds into a behavioral context layer that informs how an SDR sequences their outreach without inflating the score that determines whether a lead reaches sales at all.
The data quality work has to happen in parallel. Duplicate records, stale engagement history, and incomplete firmographic fields all introduce variance that the model interprets as signal. Time-decay functions, typically exponential, should be applied to all behavioral inputs with the decay rate calibrated to your average sales cycle length, so that a lead who visited your pricing page nine months ago and has since gone completely silent does not continue to occupy the top of the queue.
When those two things are true, the operational outcomes follow in a way that is genuinely measurable. MQL-to-SQL conversion rates improve because the leads crossing the threshold have demonstrated real purchase-adjacent behavior rather than accumulated points through bot clicks and nurture email opens. SDR capacity stops being wasted on contacts who were never going to take a meeting. Marketing attribution becomes defensible because every MQL can be traced to a specific high-intent action rather than a composite score that nobody outside rev ops can explain.
And then something less quantifiable happens, which is that the pipeline review conversation changes. Sales stops saying the leads aren’t ready, because the leads that arrive in their queue actually are. Marketing stops pointing to a scoring dashboard as a shield, because the model no longer needs defending. The standoff that opened this post, the one where a real prospect from a real target account sits untouched for two weeks while both teams argue about whose model is correct, stops happening as often, not because anyone called a truce, but because the model stopped giving both sides something to fight about. That is what genuine sales and marketing alignment looks like in practice, and a better lead scoring model is often what gets you there.
Frequently Asked Questions
How often should you update your lead scoring model? At minimum, every 90 days. Buyer behavior shifts, your ICP evolves, and signals that correlated with closed-won deals six months ago may have weakened. The practical trigger is simpler: if your sales team is rejecting more than 30 percent of MQLs, the model needs recalibration before it does more damage to sales and marketing alignment.
What is a good MQL-to-SQL conversion rate for B2B SaaS? The industry average sits at around 13 percent, but that number is dragged down by teams running noisy models. Companies with mature lead scoring built around intent signals rather than activity metrics consistently achieve MQL-to-SQL conversion rates in the 20 to 32 percent range, with top performers reaching 40 percent when scoring is paired with tight sales follow-up SLAs.
What is the difference between a lead score and a lead grade? A lead score measures behavioral engagement: what a lead has done and how recently they did it. A lead grade measures fit: how closely a lead matches your ideal customer profile based on firmographic and demographic attributes. The most reliable models separate these two dimensions and require a lead to clear a minimum threshold on both before being passed to sales, rather than allowing a very high score on one to compensate for a failing grade on the other.




